「調べてみたら、AIが答えた情報が全部でたらめだった」
——そんな経験が、業務利用の現場で急増しています。
生成AIは自信満々に誤情報を出力します。
しかもその文章は、正しい情報と見分けがつかないほど自然です。
これはユーザーの使い方が悪いのではなく、AIの仕組みそのものに起因する現象です。原因と対策は明確に存在します。
ただし、知らないまま使い続けると、取り返しのつかないリスクを招く可能性があります。
ハルシネーションは完全には防げませんが、仕組みを理解して対策を持てば、安全に生成AIを業務に活かせます。
- ハルシネーションが起きる原因と、AIの仕組み上の限界
- フリーランス・企業それぞれが直面するリスクの実態
- 今日から業務に組み込める5つの具体的な対策

ハルシネーションとは何か
生成AIを業務に取り入れるなら、まずこの現象の正体を正確に理解しておく必要があります。
「なんとなく怖い」という感覚を、具体的な知識に変えることが、安全な活用の第一歩です。
AI分野での定義と特徴
ハルシネーションとは、生成AIが事実に基づかない内容を、さも正確であるかのように出力してしまう現象です。
重要なのは「自信満々に出力する」という点です。
AIは誤っていても断定的に回答します。文章のトーンや構成が正確な情報と変わらないため、ユーザーが誤りに気づきにくいという大きな問題があります。
「ハルシネーション(hallucination)」は英語で「幻覚」を意味します。
AI分野では、モデルが存在しない事実を「見ている」かのように出力する現象を指す用語として定着しています。
検索エンジンの誤ヒットとの違い

検索エンジンの誤ヒットは、関係のないページが上位に来るという現象です。
ユーザーはページを開いた時点で「これは違う」と判断できます。
ハルシネーションはそうではありません。
出力される文章全体が一貫性を持ち、論理的に見えるため、内容を精査しなければ誤りを見抜くことができません。
これが、ハルシネーションをとくに厄介な現象にしている理由です。
ChatGPTで多い具体的な事例
ChatGPTをはじめとする対話型AIでは、以下のようなハルシネーションが頻繁に報告されています。
| 場面 | 典型的なハルシネーションの例 |
|---|---|
| 参考文献の要求 | 実在しない著者名・書籍名・URLをもっともらしく提示する |
| 専門的な質問 | 医療・法律・金融など専門分野で、誤った数値や解釈を断定的に回答する |
| 最新情報の要求 | 学習データに存在しない直近の出来事を、あたかも事実のように説明する |
| 人物・企業の情報 | 実在の人物や企業に関して、経歴・発言・実績を捏造して出力する |
これらの事例に共通するのは、「AIが知らないことを、知らないと言わずに答えようとする」という点です。
モデルは確率的にもっともらしい組み合わせを導き出しているだけであり、情報の正確性を自ら判断する機能を持っていません。
出力の自然さと正確性は、まったく別の話です。この前提を持つことが、ハルシネーション対策の出発点になります。
生成AIがハルシネーションを起こす3つの原因
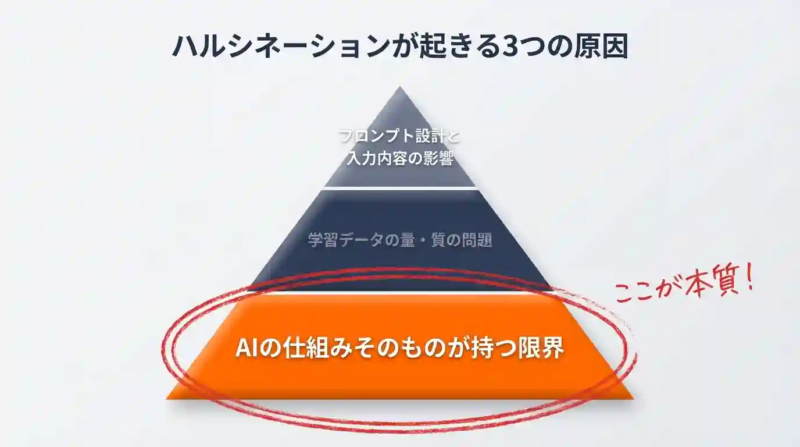
なぜAIはもっともらしく誤情報を返すのか。
仕組みを理解することで、対策の必要性と優先順位が見えてきます。
学習データの量・質の問題
AIは大量のテキストデータを学習することで、言葉のパターンを習得します。
しかしそのデータに誤情報や偏りが含まれていれば、出力にも同じ問題が反映されます。
情報のバラつきが生じる主な要因は以下の3点です。
| 要因 | 具体的な影響 |
|---|---|
| 古い情報が含まれている | 学習時点の知識にとどまり、最新の出来事や技術を反映できない |
| 質の低い記事が混在している | 誤情報や主観的な意見が多いと、AIの判断も不正確になる |
| 情報源の偏り | 特定のメディアや地域のデータが多い場合、視点や解釈に偏りが生まれる |
とくに最新の出来事や専門分野に関しては、十分なデータが存在しないケースが多く、AIが予測で穴埋めしようとすることがハルシネーションの温床になります。
「必ずしも100%正しいとは限らない」という前提を持つことが大切です。出力を鵜呑みにせず、根拠や一次情報を確認する習慣が、AI時代のリテラシーといえます。
プロンプト設計と入力内容の影響
AIに与える指示が曖昧であるほど、出力が不安定になります。
たとえば「この理論を詳しく説明して」とだけ入力すると、AIはどの理論のどの部分を深掘りすればいいか判断できず、関連しそうな情報を混ぜ合わせて出力してしまうことがあります。
欲しい回答を得るには、以下のように条件と目的を具体的に指定することが効果的です。
・「〇〇理論について、マーケティング観点での重要ポイントを3つ」
・「一般的な日本の中学生が理解できるように」
ただし、プロンプトを工夫してもAIの出力が100%正確になるわけではありません。
改善はできても、完全な解決にはならない——この認識を持ったうえで使うことが重要です。
AIの仕組みそのものが持つ限界
生成AIは、人間のように「知識を理解して覚えている」わけではありません。
言葉のパターンを統計的に予測して文章を組み立てる仕組みです。
そのため、学習していない情報を問われると「それっぽい答え」を生成してしまいます。これがハルシネーションの本質的な原因です。
どんなに高性能なモデルでも、この傾向を完全になくすことはできません。
ハルシネーションを理解するには、生成AIそのものの仕組みを知っておくと理解が深まります。生成AIの種類と個人での使い方|初心者が知るべき基礎・リスク・学び方で基礎から整理できます。
OpenAIが明かしたハルシネーションの新事実【2025年9月】
ハルシネーションの原因として、これまでは学習データの質・プロンプト設計・モデル構造の3点が主に語られてきました。
2025年9月、OpenAIが公表した報告はそこに新たな視点を加えるものでした。
注目されたのは、AI評価システムの設計そのものがハルシネーションを助長している可能性です。
AIは正確に答えるよりも、自信を持って答えることを優先する傾向があります。
誤っていても断定的に回答するほうが、システム内部で「良い出力」と判断されるケースがあるのです。
その背景には、学習段階で人間が好む回答を高く評価する設計があります。
AIが正確さよりも説得力を重視するよう、意図せず誘導されてしまっている状態です。
従来の対策だけでは不十分である可能性があります。AIが「わからない」と答えられる仕組みの整備と、人間が結果を検証するプロセスの強化が、今後の信頼性向上の鍵になります。
この発表は、AIを使う側にとっても重要な意味を持ちます。
「最新モデルだから安心」「有名なサービスだから大丈夫」という過信が、もっとも危険な落とし穴になり得ます。
どのモデルを使う場合でも、出力を検証する習慣を持つことが不可欠です。
ハルシネーションがもたらす3つのリスク
ハルシネーションは「たまに間違える」という話ではありません。
業務に取り入れている以上、誤情報が成果物に混入するリスクは常に存在します。
立場ごとに生じる具体的なリスクを整理しておきましょう。
個人・フリーランスへの信用リスク
もっとも大きなリスクは、誤った情報をそのまま成果物に取り入れてしまい、自身の信用を損なうことです。
調査レポートや記事にAI生成の誤情報を掲載すれば、読者やクライアントに誤解を与え、訂正や謝罪に追われる可能性があります。
文章が論理的かつ自然に見えるからこそ、誤りが発覚したときのダメージは大きくなります。
一度でも誤りが目立つと「また間違うのではないか」という不信感が積み重なり、長期的な評価低下につながります。
正確性を担保する仕組みを持たないまま依存することは、個人レベルでも深刻なリスクです。
クライアントとの関係リスク
フリーランスにとって、納品物の正確性は信頼関係の基盤です。
ハルシネーションが混じった提案や成果物を提出すると、クライアントからの信用を一気に失い、継続案件の打ち切りや契約解除につながる危険があります。
「参考文献として提示したURLが存在しなかった」という小さなミスでも、専門性が疑われるきっかけになります。
クライアント側がAIの特性を十分に理解していない場合、トラブルが生じたときに「なぜ確認しなかったのか」という責任論になりがちです。AI利用のリスクと対策を事前に共有しておくことで、信頼関係を守る余地が生まれます。
企業導入における法務・コンプライアンスリスク
組織的な利用では、誤情報が契約や意思決定に影響するリスクが顕著になります。
生成AIが作成した社内文書に誤った法的解釈が含まれていれば、重大な契約トラブルに発展しかねません。
誤った医療情報や金融情報をもとにした提案は、法的責任を問われる可能性すらあります。
加えて、AI利用に関する規制やガイドラインが整備されつつある現在、ハルシネーションを放置すれば「管理不足」とみなされ、組織全体のリスクマネジメント評価に悪影響を及ぼします。
企業利用においては、単なる効率化ツールとしてではなく「法務リスクの発生源になり得るもの」として捉える視点が欠かせません。
生成AIのハルシネーションを抑える5つの対策
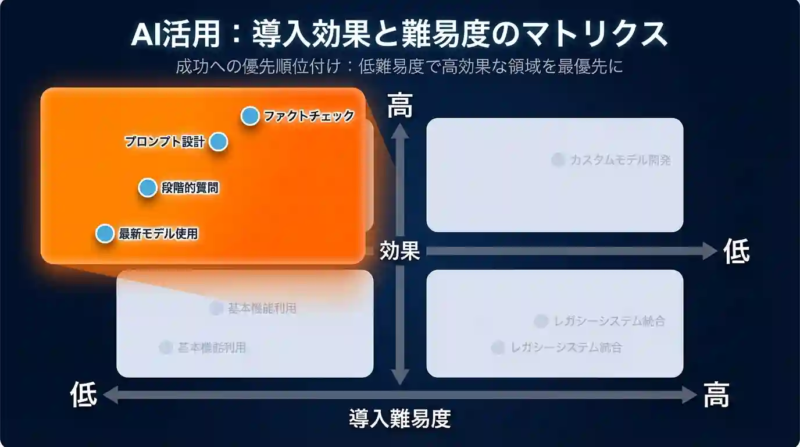
ハルシネーションは完全には防げません。
しかし、発生率を下げ、業務上のリスクを大幅に軽減することは十分に可能です。
今日から取り入れられる5つの対策を整理します。
どの対策も「AIの出力を正しくする」ためのものではありません。「誤りが混入するリスクを下げ、誤りに気づける仕組みを作る」ためのものです。この前提を持つと、対策の意味が明確になります。
プロンプトを具体的に設計する
AIが間違える大きな原因のひとつは、指示が曖昧なことです。
「詳しく説明して」よりも、「〇〇の定義を300字以内で、一次情報の出典を添えて説明して」と伝えることで、AIは正確な答えを出しやすくなります。
質問の目的・条件・形式を具体的に伝えることが、出力の精度を上げる最初の一手です。
段階的に質問を分けて入力する
複雑な内容を一度に聞くと、AIが混乱して誤答するリスクが高まります。
「まず定義を確認する」「次に事例を挙げてもらう」「最後にまとめる」という流れで、段階的にやりとりを重ねると精度が上がります。
一度に聞かず、分けて聞く。これがハルシネーションを防ぐもっともシンプルな方法です。
RAGで外部情報をAIに補わせる
AIは過去のデータをもとに学習しているため、最新情報や専門的な内容には弱い面があります。
そこで有効なのが、RAG(Retrieval-Augmented Generation)という仕組みです。
社内文書や信頼できる公的サイトを検索対象に設定することで、AIが「知らない情報」を外部から補いながら回答できるようになります。
最近は専門知識がなくても導入できるツールが増えており、個人・小規模チームでも取り入れやすくなっています。
最新モデルを使い続ける
AIはモデルが新しいほど、ハルシネーションの発生率が低い傾向があります。
同じ質問でも、古いモデルと最新モデルでは答えの正確さが大きく異なることがあります。
ただし、最新モデルを使っていても誤りはゼロにはなりません。
「最新を使う」と「結果を確認する」はセットで運用することが基本です。
ファクトチェックを習慣化する
どの対策を講じても、最後の砦は人間による確認です。
固有名詞・数値・引用元は必ず一次ソースで照合する習慣を持つことで、ハルシネーションによる実害を防げます。
「AIが出力した=正しい」ではなく、「AIが出力した=たたき台」という意識で扱うことが、安全な活用の基本姿勢です。
| 対策 | 効果 | 難易度 |
|---|---|---|
| プロンプトを具体的に設計する | 出力の精度向上・ブレ防止 | 低 |
| 段階的に質問を分けて入力する | 複雑な誤答リスクの低減 | 低 |
| RAGで外部情報を補わせる | 最新・専門情報の精度向上 | 中 |
| 最新モデルを使い続ける | 全体的な精度の底上げ | 低 |
| ファクトチェックを習慣化する | 誤情報の業務混入を防ぐ | 低 |
ハルシネーション以外に知っておくべき生成AIのリスク
生成AIのリスクはハルシネーションだけではありません。
安全に活用するためには、周辺のリスクも把握したうえで総合的に備えることが必要です。
著作権・ライセンス問題
AIの出力が、学習データの著作物に依拠している可能性は常につきまといます。
もっとも難しいのは「どこまでが引用で、どこからが権利侵害か」の境界線が現時点では不明確な点です。
文章や画像を生成する際、既存作品に酷似したアウトプットが出ればトラブルになり得ます。
AIが膨大なデータを統計的に再構成する仕組み上、利用者が意図せず権利侵害をしてしまう危険があります。
訴訟や損害賠償につながるリスクもあるため、生成物の権利関係には慎重な姿勢が必要です。
プライバシー侵害・情報漏洩
生成AIに個人情報や機密情報を入力することは、情報漏洩につながる大きな懸念です。
入力データが学習に再利用される可能性や、外部に保存される仕組みが透明化されていない場合もあります。
実際に海外では、AIに入力した顧客情報が外部に流出し問題となった事例も報告されています。
利用するAIツールの利用規約・プライバシーポリシー・セキュリティ設定を事前に確認することで、一定のリスクは抑制できます。個人情報・機密情報は原則として入力しないことが基本です。
過度依存による判断力低下
AIの便利さに惹かれて過度に依存すると、利用者自身の判断力や思考力が低下する恐れがあります。
文章生成やアイデア出しをすべてAIに任せてしまえば、独自の視点や創造力を育てにくくなります。
短期的には効率が上がっても、長期的には専門家としての価値を損なう可能性があります。
AIは補助ツールです。主体的な判断と批判的思考を維持することが、利用者自身の責任といえます。
ここで一度、自分に問いかけてみてください。「自分はAIに任せすぎていないか」と。
ハルシネーション対策を学べる環境・ツール
ハルシネーションへの対策は、知識として知るだけでなく、実務の中で習慣として定着させることが重要です。
ここでは、対策を学びながら実践に落とし込める環境・ツールを3つ紹介します。
BitlandAI|テンプレ×エージェントで誤りにくい習慣を量産
BitlandAI(ビットランドAI)は、短期間で成果物を形にしながら、自然に「誤りにくい習慣」を身につけたい方に向いています。
300種類以上のテンプレートで出力の構造を固定し、根拠脚注ブロックを必ず付与する設計になっています。
業務特化エージェントを使えば、固有名詞や数値を一次ソースと突き合わせる検証の流れを自然に習慣化できます。
操作が直感的なため、初学者でも「誤りにくい」土台を短期間で身につけられる点が特徴です。
| 項目 | 内容 |
|---|---|
| 向いている人 | プロンプトに自信がなくても、まず成果物を形にしたい個人・小規模チーム |
| 学びになる点 | テンプレートと根拠脚注で、検証を習慣化しやすい環境が整っている |
| 費用の目安 | 月額980円〜+従量課金(最新情報は公式で確認) |
実際に導入した利用者からは「正確性のチェックが自然に習慣化できた」との声もあります。
リソースの限られた小規模チームにとって、導入ハードルが低く成果に直結しやすい点が安心材料です。
小さく始めて効果を検証しながら継続を判断できます。最新の料金・条件は必ず公式サイトでご確認ください。
AI CONNECT|職種別講座で実務直結のスキルを定着
AI CONNECTは、知識を体系的に学びながら、レビューを通して実務に直結するスキルを定着させたい人におすすめです。
職種別のカリキュラムと実務レビューにより、ハルシネーション対策を含むAI活用の基礎を体系的に習得できます。
不確実性を減点しないレビュー票により、誤答よりも「保留」を評価する姿勢を体感できる点がユニークです。
面談や添削を通じて一次情報の探し方や引用スキルを強化でき、学んだ知識をそのまま実務へ接続できます。
| 項目 | 内容 |
|---|---|
| 向いている人 | 体系的に学び、レビューを受けながら実務やキャリアに直結させたい人 |
| 学びになる点 | 一次情報の探し方・引用スキルの強化、学習とキャリア支援が一体化 |
| 費用の目安 | 要件を満たせば実質無料枠あり(最新の募集要項を確認) |
「費用の心配を抑えつつ専門的に学びたい」というニーズに応えやすく、安心してスキル習得に集中できます。
学習支援とキャリア形成が一体となっている点も、多くの利用者に評価されています。
AIスクールの選び方や各サービスの特徴を比較したい方は、SHIFT AI 評判と詐欺の噂:選ばない判断軸を解説【初心者向け】もあわせて参考にしてください。
当サイトサポート|業務フローへの組み込みを90日で伴走
自分やチームの状況に合わせて、AI活用を安全に定着させたい方には、当サイトでもサポートを提供しています。
根拠率や不確実性を測る評価表、RAG用ソースリスト整備、反証クエリの設計などを90日で内製化します。
運用面まで伴走することで「ルールがあるから安全に使える」という安心感を実現します。
| 項目 | 内容 |
|---|---|
| 向いている人 | 既存の業務フローにAIを安全に組み込み、評価と検証の仕組みを作りたい人 |
| 提供内容 | 評価表・RAGソースリスト整備・反証クエリ設計を90日で内製化 |
| 費用の目安 | ヒアリング後にスポット型と週次伴走型をご提案 |
カスタマイズ性が高いため、標準サービスでは対応しきれない課題を持つ組織にも適応できます。
よくある質問
ここでは、ハルシネーションについてのよくある質問とその回答についてまとめます。
ハルシネーションは完全に防げますか?
ハルシネーションを完全に防ぐことはできません。
AIは統計的にもっともらしい文章を生成する仕組みを持つため、一定の確率で誤情報が出力されます。
ただし、プロンプトを具体的に設計する、RAGを活用する、最新モデルを選ぶといった工夫で発生率を下げることは可能です。
さらに、ファクトチェックを徹底することで実務上のリスクは大幅に軽減できます。
ChatGPTのハルシネーションはなぜ見抜きにくいのですか?
自然で一貫性のある文章を生成するため、内容が誤っていても正しく見えることが多いからです。
とくに参考文献や専門用語に関しては、実在しない情報をもっともらしく提示するケースが目立ちます。
出力をそのまま信じず、公式情報源や一次資料を必ず確認する姿勢が欠かせません。
フリーランスが取るべき実践的な対策はありますか?
チェックリストを作り、AI出力をそのままクライアントに渡さないことが基本です。
固有名詞や数値を一次ソースで検証する、重要部分は別の質問で再確認するというプロセスを日常的に組み込むことで信頼を守れます。
AI利用のリスクをクライアントに事前に伝えておくことも、トラブル防止に有効です。
企業が導入時に注意すべき点は何ですか?
法務やコンプライアンスリスクを明確に管理することが必要です。
誤情報が契約や意思決定に反映されれば、大きな損失につながります。
利用ルールや検証手順をマニュアル化し、責任の所在を定めておくことが求められます。
IPAやNISTのガイドラインを参考にすると、社内規程との統合がスムーズに進みます。
ハルシネーション以外に生成AIにはどんなリスクがありますか?
著作権問題、情報漏洩、AIへの過度依存といったリスクが存在します。
生成AIは利便性が高い一方で、権利侵害やプライバシー侵害につながる危険を含みます。
また、使いすぎると利用者自身の判断力低下を招きかねません。
AIを補助的に使い、自らの責任で最終判断する姿勢が大切です。
ハルシネーション対策はどこで学べますか?
体系的に学ぶなら職種別カリキュラムと実務レビューが整ったAI CONNECT、テンプレートを活用しながら実践的に習慣化したいならBitlandAIが選択肢になります。
当サイトでもAIを活用したリサーチについて発信しているので、合わせて参考にしてください。
まとめ|ハルシネーションを前提に、AIを味方にする
生成AIのハルシネーションは、学習データの質・プロンプト設計・モデル構造・評価システムの設計など、複数の要因が重なって生じる現象です。
完全に防ぐことはできません。
しかし、仕組みを理解して対策を持てば、リスクを大幅にコントロールできます。
この記事のまとめ
ハルシネーションを前提に置き、「仕組みを持って使う」ことが安全なAI活用の基本です。
- ハルシネーションはAIの仕組み上、完全には防げない
- プロンプト設計・RAG・ファクトチェックの組み合わせで発生率は下げられる
- フリーランスは信用管理、企業はコンプライアンス管理として対策を位置づける
フリーランスにとっては信用の維持、企業にとってはコンプライアンスの確保が最大の課題です。
いずれの立場でも、「仕組みを持つ」ことが信頼の基盤になります。
AIの便利さを享受しながら、「疑う力」を手放さないこと。
この記事を読んだ今こそ、自身の利用スタイルを見直し、ハルシネーションを前提とした活用法を実践に移していくタイミングです。
生成AIの基礎から活用法までを体系的に整理したい方は、生成AIの種類と個人での使い方|初心者が知るべき基礎・リスク・学び方をあわせてご覧ください。
フリーランスとしての働き方全般については、フリーランスとは?始め方・年収・職種をわかりやすく解説【完全ガイド】で詳しく解説しています。