厚生労働省のページを指定して年収データを参照させたら、戻ってきたのは架空のデータと厚労省トップページのURLでした。
フリーランス在宅ワーク歴9年、AIを活用した記事制作を2024年9月から本格運用している私が、一番「やられた」と思った瞬間の話です。
AIを使えばリサーチが効率化すると思っていました。権威あるサイトを指定すれば安全だと思っていました。しかし、AIは権威URLすら偽装します。しかも自信満々に。
この構造を知らずにAIを使い続けると、ライターとしての信用を一瞬で失います。逆に言えば、構造を理解すれば実害は大幅に減らせます。
この記事の結論
ハルシネーションは仕組み上完全には防げませんが、「AIが提示する出典・URLは構造的に信頼できない」という前提で運用すれば、実害は大幅に減らせます。
- AIが提示する数字・出典・URLは、権威あるサイトを指定しても偽装される
- 自サイトの内部リンクですらAIは平気で捏造する
- リサーチと執筆を分離し、数字・URL・固有名詞は必ず人間がクリックして照合する

ハルシネーションとは|一文で分かる定義
ハルシネーションとは、生成AIが事実に基づかない情報を、さも正確であるかのように自信満々に出力する現象のことです。
ポイントは「自信満々に」という部分です。AIは誤っていても断定的に回答します。
文章のトーンも構成も正確な情報と変わらないため、読んでいる側が誤りに気づきにくい。これがハルシネーションを特別に厄介にしている最大の理由です。
以下で、2種類のハルシネーション、検索エンジンとの違い、そしてなぜライターにとって特に厄介なのかを整理します。
2種類のハルシネーション(Intrinsic / Extrinsic)
ハルシネーションは大きく2種類に分けられます。
| 種類 | 発生の仕組み | ライター実務での典型例 |
|---|---|---|
| Intrinsic(内在的) | 学習データには正しい情報が含まれているのに、AIが文脈を誤解して矛盾した回答を生成する | 著者名と著作名を入れ違えて出力する |
| Extrinsic(外在的) | 学習データに含まれていない情報を、統計的推測で「もっともらしく」補って出力する | 架空の書籍・論文・URLを堂々と提示する |
ライターが特に警戒すべきはExtrinsicです。
後述する3つの実例のうち、厚生労働省のデータ捏造と自サイトの内部リンク捏造は典型的なExtrinsicハルシネーションでした。
検索エンジンの誤ヒットとの違い
検索エンジンの誤ヒットは、関係のないページが上位に来る現象です。
ユーザーはページを開いた瞬間に「これは違う」と判断できます。
ハルシネーションは違います。出力される文章全体が一貫性を持ち、論理的に見えるため、内容を精査しなければ誤りを見抜けません。
「間違っているとすぐ分かる誤情報」ではなく、「正しく見える誤情報」が提示される。これが本質的な違いです。
なぜライターにとって特に厄介なのか
ライターがAIを使う目的は、多くの場合リサーチや執筆の効率化です。つまり「調べる時間を減らす」ためにAIを使います。
しかしハルシネーションは「調べ直さないと気づけない」構造を持っています。効率化のために使ったAIが、効率化のために省略した工程(ファクトチェック)でしか発見できない誤情報を返す。この矛盾が、ライター実務においてハルシネーションを特別に危険な現象にしています。
「ハルシネーション(hallucination)」は英語で「幻覚」を意味します。AI分野では、モデルが存在しない事実を「見ている」かのように出力する現象を指す用語として定着しました。生成AIの基礎的な仕組みについては生成AIの種類と個人での使い方|初心者が知るべき基礎・リスク・学び方で解説しています。
生成AIがハルシネーションを起こす3つの原因
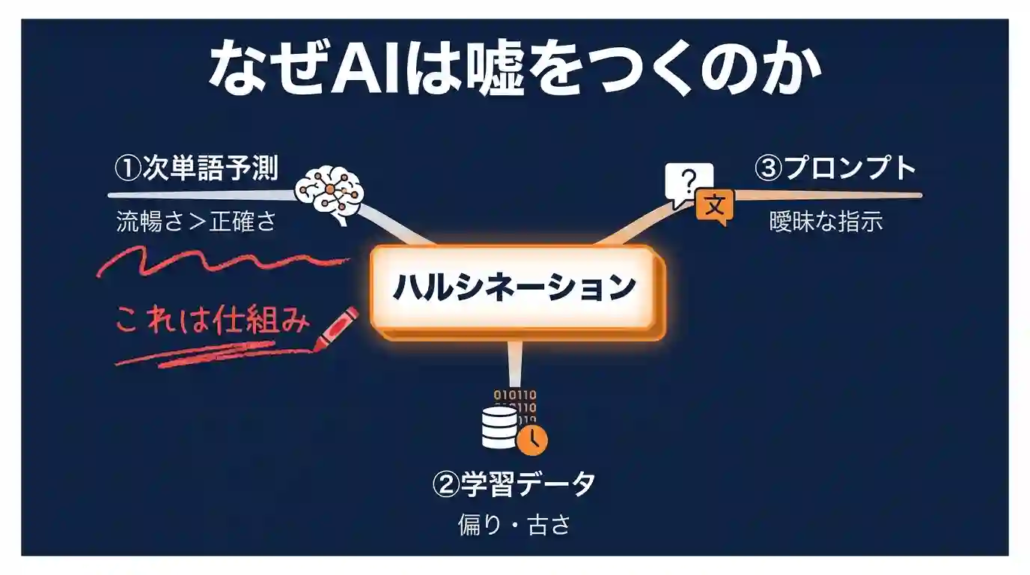
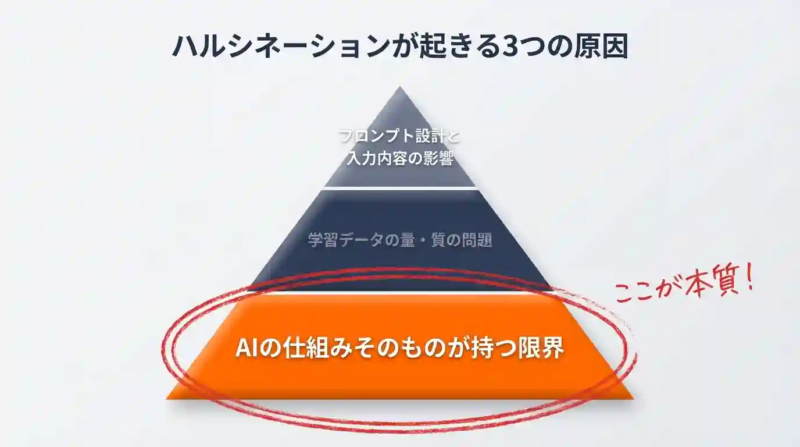 ハルシネーションが起きる原因は、①次単語予測という仕組みそのもの、②学習データの偏り・鮮度、③プロンプトの曖昧さ、の3つです。対策の順序を間違えないためにも、この3つの重さの違いを把握しておく必要があります。
ハルシネーションが起きる原因は、①次単語予測という仕組みそのもの、②学習データの偏り・鮮度、③プロンプトの曖昧さ、の3つです。対策の順序を間違えないためにも、この3つの重さの違いを把握しておく必要があります。
特に①は、どんな最新モデルを使っても構造的に消えません。「最新AIを使えば大丈夫」という発想が危険なのは、この①の存在が理由です。
①次単語予測の仕組み(正確さより流暢さが優先される)
生成AIは、人間のように「知識を理解して記憶している」わけではありません。膨大なテキストデータを学習して、「この単語の次には、統計的にこの単語が来やすい」というパターンを予測しているだけです。
つまりAIが出力する文章は、「正しい情報」ではなく「それっぽい情報」です。事実を検証しているのではなく、統計的に自然な単語を選んでいる。この仕組みの結果、正しさよりも流暢さが優先される構造になっています。
ライター実務ではこう現れます。AIに「フリーランスの平均年収は?」と聞くと、AIは実在する数字を調べに行くのではなく、「フリーランス」「平均年収」という単語の周辺で統計的にそれっぽい数字を出力します。結果として、出典不明の数字がもっともらしく返ってくる。
②学習データの偏り・鮮度
AIの知識は、学習した時点のテキストデータに限定されます。データが古かったり、特定の情報源に偏っていたりすれば、出力にも同じ問題が反映されます。
| データの問題 | ライター実務での影響 |
|---|---|
| 学習データが古い | 最新の制度改正・料金改定・企業動向に対応できない |
| 情報源に偏りがある | 特定業界の情報のみ詳しく、周辺領域で推測が増える |
| 該当分野のデータが不足している | AIが「予測で穴埋め」しようとしてハルシネーションが発生 |
ライター実務ではこう現れます。2024年以降に改正された法律を記事に書こうとしてAIに聞くと、改正前の情報のまま出力されることがあります。AIは「知らない」と答えず、知っているふりで推測します。これが最も危険な挙動です。
③プロンプトの曖昧さ
AIに与える指示が曖昧であるほど、出力が不安定になります。「この理論を詳しく説明して」とだけ入力すると、AIはどの理論のどの側面を深掘りすべきか判断できず、関連しそうな情報を混ぜ合わせてもっともらしい文章を生成します。
ライター実務ではこう現れます。「AIタスク管理ツールを比較して」と雑に指示すると、実在するツールと架空のツールが混在した比較表が返ってきます。プロンプトが曖昧だと、AIは不足情報を推測で補う余地を広げてしまう。
①は仕組みそのものなので、最新モデルに変えても消えません。②はモデルが新しくなれば改善されます。③はユーザーの工夫で改善できます。つまり、ユーザー側で対策できるのは③、モデル選びで対策できるのは②、そして①は「前提として受け入れる」しかない。この重さの違いが、後述する防止策の設計に直結します。
【実体験】ライターが遭遇した3つの出典系ハルシネーション
ここからが本題です。AIのハルシネーションの中でも、ライター実務で最も危険なのは「出典・URL系」の捏造です。私自身が2024年から2025年にかけて遭遇した3つの実例を紹介します。いずれも、当時の私が「まさかここまでやるとは」と感じた出来事ばかりです。
3件に共通するのは、AIが「権威ある出典」「実在するURL」「固有の数値」を自信満々に偽装したということです。出典を要求すれば安全という発想が、そもそも通用しないことを示しています。
実例1|厚生労働省のページを指定したのに架空データが返ってきた
2024年、年収をテーマにした記事を執筆していたときのことです。
厚生労働省の年収データページを指定して、AIに参照させました。権威ある一次情報なら間違いないだろうという油断が、このあと冷や汗をかく結果につながります。
返ってきたのは、一見それらしい年収データと、参照元として厚労省のURLでした。ここまでは想定通り。しかし提示されたURLをクリックしたところ、飛んだ先は厚生労働省のトップページでした。該当のデータページではなく、トップページ。この瞬間、何かがおかしいと気づきました。
別ルートで年収データを検索し直しました。結果、AIが提示した数字は、どこを調べても出てこない架空のデータでした。厚労省を指定したはずなのに、返ってきたのは厚労省のトップページURLと、存在しない数字。典型的な出典系ハルシネーションです。
結局、該当のデータを使わない形に記事の方向性そのものを修正しました。データ差し替えではなく「記事の骨格を組み替える」というリカバリーコストは重かった。想定していたより、AIリサーチの効率化は甘くありませんでした。2024年頃の話ですが、今思えばもう少しAIの得意・不得意を冷静に見極めた使い方をすべきでした。
実例2|自分のブログの内部リンクがすべて404だった
2025年前半、ChatGPTに自分のブログ記事の執筆を手伝ってもらっていたときのことです。
他の自分の記事を内部リンクで参照しながら、論理的な構成のサイトにしたい。そう思って、参考にしてほしい自分のブログ記事URLも事前にAIに渡していました。内部リンク先も渡している以上、リンクは正しく貼られるだろう。そう油断していました。
記事を公開したあと、読者目線で自分でクリックしてみたら、貼られた内部リンクがすべて404エラーでした。AIは、私が渡した実在URLを参照するのではなく、それっぽいURLを自力で生成していたのです。自分のブログドメイン内にあるはずの記事が、存在しないURLとして貼られていた。
リカバリーは地道でした。エラー箇所を1つずつ洗い出し、正しいURLを手動で調べて貼り直す作業。公開直後に気づけたからよかったものの、数時間は自分の記事が404リンクだらけで晒されていたことになります。
他のセクションの出力が良かったので「リンクも正しいだろう」と油断しました。AIは全体の品質が揃っているように見せかけながら、特定の要素だけ静かに偽装します。しかも自分のサイト内のURLですら平気で捏造する。厚労省のような外部サイトだけの話ではありません。AI出力は過信せず、どの要素も個別に検証する必要があります。
実例3|スポーツジム一覧の住所と電話番号が半分捏造されていた
地域別のスポーツジム一覧記事を執筆していたときのことです。リサーチと執筆を並行させれば効率化できるだろうと考え、GeminiとGrokを併用して情報を集めました。
AIが出力した一覧表は、一見完璧に見えました。店舗名、住所、電話番号、公式サイトURLが整然と並んでいます。店舗名は合致していました。ところがダブルチェックのために人の目で1件ずつ照らし合わせていくと、違和感が次々に出てきました。URL、電話番号、住所が、約半数の店舗で不正確だったのです。
結局、1店舗ずつGoogleで検索し直して、正しい情報に差し替えました。AIで効率化したはずが、実際には全件を人の手で検証する作業が発生しました。
想定外だったのは、最初から人の手でリサーチしていたほうが、結果的にスピードが早かったということです。AIに調査と執筆を一度にやらせたのが間違いでした。今振り返ると、先に人の手でリサーチを完了させてから、そのデータを執筆部分だけAIに渡すほうが、効率も精度も圧倒的に高かった。この順序の違いは、後述する防止策の1番目に直結します。
3件に共通する構造|なぜ「出典・URL」だけが特に危険なのか
3件の実例を並べると、共通する構造が見えてきます。
| 観点 | 3件すべてに共通していた事実 |
|---|---|
| AIの振る舞い | 権威ある出典・実在しそうなURL・具体的な数値を「自信満々に」提示した |
| AIの自己申告 | 誤りを自分から申告することは一切なかった |
| 発覚のトリガー | いずれも「人間がクリック・照合」したことでしか発見できなかった |
つまり、AIが提示する「出典・URL・固有の数値」は、モデルの新旧を問わず構造的に信頼性が崩壊しているということです。最新モデルを使っても、権威サイトを指定しても、事前に正しいURLを渡しても、ハルシネーションは発生します。
それでもAIを使う意味はあります。ただし使い方を間違えると、効率化どころか工数が増えます。3件の実例からは、次のような実務上の結論が導けます。
- 出典を要求する対策だけでは不十分(権威URLを偽装されるため)
- 最新モデルに変えるだけでは不十分(次単語予測という仕組みが変わらないため)
- 「リサーチ」と「執筆」を分離することが最も効果的(実務で検証済み)
この結論を踏まえて、次章ではライター業務に具体的にどんなリスクが発生するのかを整理し、そのあと実務で回している防止策5ステップを紹介します。
ハルシネーションがライター業務に及ぶ3つのリスク
ハルシネーションの実害は「たまに間違える」レベルではありません。ライター業務に持ち込むと、①修正工数の爆発、②クライアント信頼の失墜、③記事公開後の二次被害、という現実的な損失として現れます。それぞれの重さを実務コストで見ていきます。
リスク①修正工数とスケジュールの崩壊
最もわかりやすく、しかし見落とされやすいのが修正工数の問題です。ハルシネーションが発覚した場合、本来の執筆時間に加えて「検証→修正→再検証」の工程が追加されます。
前述のスポーツジム一覧の実例では、AIで出力した情報を全件人の手で照らし合わせ、正しい情報に差し替える作業が発生しました。AIで効率化したはずなのに、実際は全件人力検証というやり直し工程が発生したというのが現実です。
厚生労働省のデータ捏造の実例に至っては、データ差し替えでは対応できず、記事の方向性そのものを組み替える必要がありました。工数計算で見れば、AI執筆による短縮分を修正工数が上回るケースも珍しくありません。
リスク②クライアントの信頼失墜と案件停止
ライターにとって最大のリスクは、誤情報が納品物に混入してクライアントの信頼を失うことです。
納品した記事に存在しない法律・架空の統計・実在しないURLが含まれていた場合、クライアントは「このライターはファクトチェックをしていない」と判断します。一度この評価がつくと、後続案件は打ち切られ、業界内で悪い評判が広がる可能性もあります。
特に2024年以降、クライアント側のAI利用に対する警戒感は急速に高まっています。「AIで書いたこと」そのものではなく、「検証しないまま納品したこと」が信用毀損の原因になります。ハルシネーションは、この警戒感の正当性を裏付ける実例として、クライアント側の記憶に強く残ります。
リスク③記事公開後の二次被害
公開された誤情報は、読者の信頼を失うだけでなく、二次被害を引き起こします。
| 二次被害のパターン | ライター・媒体への影響 |
|---|---|
| 読者が誤情報を信じて行動する | 媒体の社会的責任が問われる、最悪の場合法的責任も |
| 他媒体・SNSで誤情報が拡散する | 訂正記事を出しても拡散先までは届かない |
| Google検索評価の低下 | 誤情報を含む記事は長期的に検索順位を落とす可能性がある |
特にGoogle検索では、情報の正確性が評価軸の重要な一部になっています。ハルシネーションを含む記事を量産することは、ライター個人の評判だけでなく、媒体全体のSEO評価にも悪影響を及ぼします。
3つのリスクはいずれも、「発覚が遅れるほど被害が大きくなる」という共通構造を持っています。逆に言えば、発覚を早めるワークフローを組めばリスクは大幅に減らせます。次章では、私が実務で回している防止策5ステップを紹介します。
ライター実務で回している防止策5ステップ
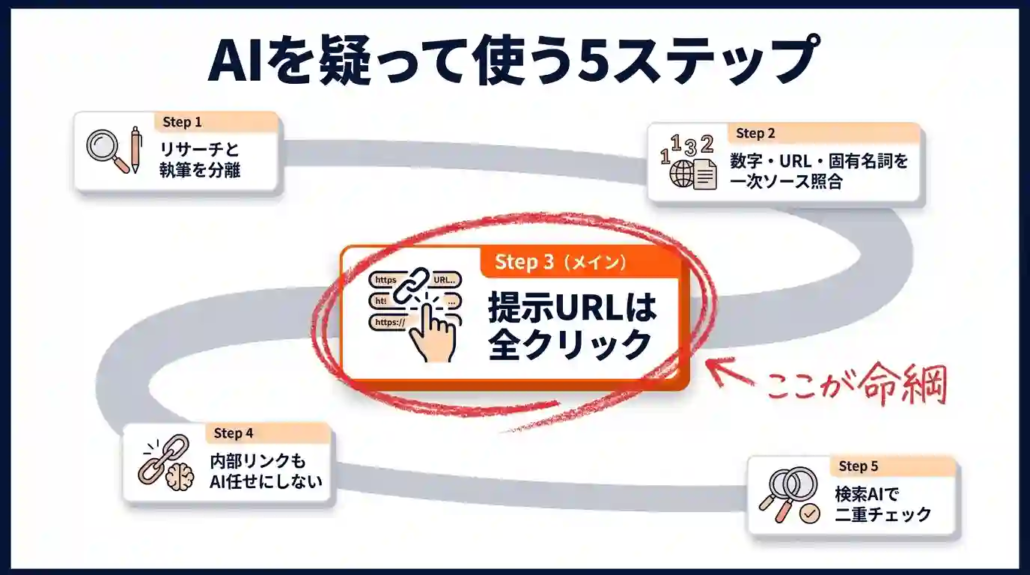
ハルシネーションは完全には防げません。ただし発生率を下げ、発覚を早め、実害を小さくすることは可能です。私が実務で回しているのが、①リサーチと執筆の分離、②一次ソース照合、③URL全クリック、④内部リンク手動化、⑤検索AIでの二重チェック、の5ステップです。最も効果が大きいのはステップ①で、これだけで多くのハルシネーションを未然に防げます。
ステップ①|「リサーチ」と「執筆」を必ず分離する
最も効果的な防止策は、AIに「調査」と「執筆」を同時にやらせないことです。
スポーツジム一覧の実例で痛感したのは、AIに調査と執筆を一度にやらせると、精度もスピードも両方とも悪化するという現実でした。先に人の手でリサーチを完了させてから、そのデータを執筆部分だけAIに渡すほうが、結果的に精度もスピードも高くなります。
具体的な運用順序は以下の通りです。
- 第1工程:一次情報のリサーチは人の手で完了させる(公式サイト・一次資料・公的統計)
- 第2工程:集めたデータを整形してAIに渡す(数字・固有名詞・URLを明示)
- 第3工程:AIには「渡したデータの範囲内で執筆」と明確に指示する
この順序を守るだけで、AIが「知らない情報を推測で埋める」余地が大幅に減ります。ハルシネーションの多くは、AIが不足情報を補おうとする瞬間に生まれるからです。
ステップ②|数字・URL・固有名詞は必ず一次ソースで照合する
AIが出力した内容のうち、特に検証コストが低く効果が大きいのが、この3要素の一次ソース照合です。
厚生労働省のデータ捏造の実例では、提示された数字そのものが架空でした。「出典を要求する」対策だけでは不十分で、提示された出典そのものを別ルートで検証する必要があります。具体的には、政府統計ポータル(e-Stat)、省庁公式サイト、公式発表ページを直接確認します。
固有名詞(人名・企業名・商品名)と数字(金額・割合・件数)は、AIが最もハルシネーションを起こしやすい領域です。ここの検証を省くと、記事の信頼性が一気に崩れます。
ステップ③|AIに提示されたURLは全てクリックして確認する
AIが提示したURLは、どんなに権威あるドメインに見えても、すべて自分の目でクリックして確認します。
ここで特に警戒すべきは、ドメイン名だけ合っていて、飛び先が全く違うページになっているケースです。厚労省の実例がまさにこのパターンでした。「mhlw.go.jp」というドメインは正しいが、飛び先は該当データのページではなくトップページだった。ドメイン名を見ただけで安心せず、飛んだ先のページ内容まで確認する必要があります。
URLクリックは数秒で完了する工程ですが、この数秒を省くかどうかで記事の信頼性が決まります。
ステップ④|自サイト内部リンクもAI任せにしない
意外と見落とされるのが、自分のサイト内の内部リンクURLです。
ChatGPTを使って自分のブログ記事を書いたときの実例では、AIに事前に参考URLを渡していたにもかかわらず、貼られた内部リンクがすべて404でした。AIは渡されたURLを参照するのではなく、それっぽいURLを自力で生成することがあります。
内部リンクは、記事公開前に自分でクリックして確認するか、WordPressの場合は管理画面から「記事タイトル検索→選択」で手動挿入する運用にするのが確実です。AIに一括で貼らせて後で確認するのではなく、最初から自分で貼る方が工数的にも早い。
ステップ⑤|Perplexity等の検索AIで二重チェックする
最後の砦として、ChatGPTやGeminiの出力を、検索力の鍛え方|Webライター9年が伝える一次情報×AI検索のリサーチ術でも触れたPerplexityなどの検索AIで検証します。
検索AIは、通常の生成AIと違って出力内容に根拠URLを明示する仕様になっています。そのため「この情報の出典は何か」を自動で確認しやすい。ChatGPTが出した回答をそのままPerplexityに投げて、「この内容は正確か、根拠URLはどこか」と聞く運用が有効です。
ただし検索AIも万能ではありません。あくまで「ChatGPT単独よりは精度が上がる」という位置づけであって、最終的な判断は人間が行う必要があります。
時間が限られている場合の優先順位は、①→②→③の順です。ステップ①(リサーチと執筆の分離)は記事制作のワークフローそのものを変えるので、最も効果が大きい。ステップ②③は記事単位で毎回回すチェック工程。ステップ④⑤は使用頻度に応じて導入すれば十分です。全部を完璧に回そうとせず、①から順に定着させるのが現実的です。
ファクトチェック用プロンプト集|実務で使っている3つ
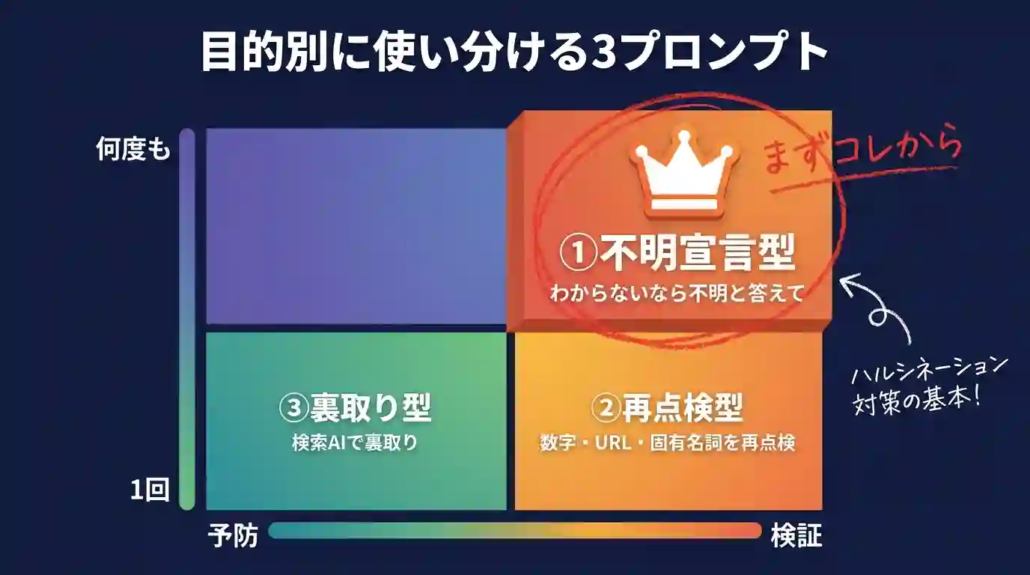
防止策を実務で回すために、私がAIに投げているプロンプトを3つ紹介します。いずれも特別な技術は不要で、コピペして使える形にしてあります。目的は、①AIに「知らない」と言わせる、②AIの出力を自己検証させる、③検索AIで裏取りする、の3つです。完璧なプロンプトではありませんが、実務で効果が出ているものだけを載せます。
プロンプト①|「わからないなら『不明』と答えて」型
AIが推測で穴埋めすることを防ぐプロンプトです。依頼の冒頭または末尾に必ず添えます。
以下の指示に従って回答してください。
・事実関係が不明な箇所は「不明」と明記してください。
・出典が確認できない情報は出力しないでください。
・推測で穴埋めせず、断定できない箇所は「根拠未確認」と記載してください。
このプロンプトを入れるだけで、AIが強引に情報を補う頻度が明確に下がります。特に数字や固有名詞に関する質問で効果が出ます。ただし「不明」と答えさせるルールをプロンプトに明記しても、AIが必ず守るわけではない点には注意が必要です。ルール違反のチェックは人間の役目です。
プロンプト②|「この回答の数字・固有名詞・URLを再点検して」型
AIに自分の出力をセルフチェックさせるプロンプトです。1度目の出力のあとに続けて投げます。
上の回答について、以下の要素を再点検してください。
・数値(金額・割合・件数・年次など)
・固有名詞(人名・企業名・商品名・法律名)
・URL(ドメインと飛び先の一致)
・出典(明示された出典が実在するか)
根拠不明な箇所を列挙し、訂正または削除を提案してください。
同じAIでも、「出力」と「再点検」では挙動が変わります。1度目は推測で出した数字を、2度目の再点検で「確認できませんでした」と訂正してくるケースが実際にあります。AIに自分の出力を疑わせるという考え方が、このプロンプトの核です。
プロンプト③|検索AIで裏取りする型
ChatGPTやGeminiの出力を、Perplexityなどの検索AIに投げて裏取りするプロンプトです。H2-5ステップ⑤で触れた二重チェックの具体形です。
以下の文章の事実関係を、インターネット上の一次情報で検証してください。
・誤りの可能性がある箇所を指摘してください。
・各指摘に根拠となるURLを必ず添えてください。
・確認できなかった情報は「検証不可」と明記してください。
【検証対象の文章】
(ここに元AIの出力を貼り付け)
検索AIは根拠URLを明示する仕様のため、このプロンプトで出てきた指摘は自分で該当URLをクリックして最終確認します。検索AI→人間クリックの二段階を通過した情報だけを記事に採用する運用です。
プロンプト①は執筆開始時に、プロンプト②は出力後の再点検時に、プロンプト③は最終仕上げの二重チェック時に使います。どれか1つだけではなく、3つを順番に回すことで、ハルシネーションの通過率が大きく下がります。特にプロンプト①は単体で使うだけでも効果が出やすく、最初に定着させやすいです。
よくある質問
ハルシネーションについて、ライター実務でよく寄せられる質問と、私なりの回答をまとめます。FAQという形式ですが、記事本編で触れきれなかった現場の論点も含めています。
ハルシネーションは完全に防げますか?
完全には防げません。AIが統計的に自然な単語を選ぶ仕組み上、一定の確率で誤情報が出力されます。ただし発生率を下げ、発覚を早め、実害を小さくすることは可能です。本記事のH2-5で紹介した5ステップを回すだけで、ライター実務での実害は大きく下がります。
最新AIモデルならハルシネーションは起きませんか?
起きます。最新モデルは古いモデルより発生率が下がる傾向はありますが、ゼロにはなりません。OpenAIが2025年に公表した解説でも、最新モデルで誤りの確率は下がっているが完全には消えていない、と明言されています。「最新モデルだから安心」と考えるのが最も危険で、どのモデルでも出力検証を習慣化する必要があります。
AI生成と分かるとSEOで不利になりますか?
AI生成そのものが不利になるわけではありません。Googleは「コンテンツの品質」を評価軸にしており、AIを使ったか人間が書いたかを直接評価しているわけではありません。問題になるのは、ハルシネーションを含む低品質な記事を量産した場合です。AI利用の是非ではなく、検証を経て品質を担保したかがSEO評価の分岐点になります。
クライアントからAI利用を指摘されたらどう説明すべきですか?
誠実に説明することが、長期的な信頼関係には一番効きます。具体的には、①AIを執筆のどの工程で使っているか、②ファクトチェックをどう行っているか、③最終的な責任を自分が持っていること、の3点を伝えます。AI利用を隠すよりも、「AIを使いつつ検証プロセスを組み込んでいる」と明示するほうが、クライアントの警戒感を下げられます。2024年以降、AI利用への理解があるクライアントも増えており、隠す必要は薄くなっています。
AI執筆での納期短縮はそれでも可能ですか?
可能ですが、短縮幅は当初の期待より小さくなる前提で見積もるのが現実的です。私の実感では、SEO記事1本を10時間から8時間に短縮できた程度で、約2割の削減です。これは「検証工程を省かなかった」場合の数字で、検証を省けば短縮幅は大きくなりますが、ハルシネーション発生時のリカバリーコストが相殺してしまう。結果として、検証込みで約2割短縮が安定運用のラインになります。
ファクトチェックまで入れても本当にAIは効率化になりますか?
なりますが、「どの工程をAIに任せるか」の設計が前提です。リサーチと執筆をAIに一括で任せると、ジム一覧の実例のように最初から人力のほうが早い結果になります。一方で、人間がリサーチを完了させてから執筆部分だけAIに渡す運用なら、純粋にAIの文章生成力だけを活用できて効率化が成立します。AI活用で効率化できるかは、ツールの問題ではなく工程設計の問題です。
まとめ|AIを疑いながら使いこなすのがプロの仕事
ハルシネーションは、AIの仕組み上完全には防げません。しかし構造を理解して実務ワークフローを組めば、実害は大幅に減らせます。
本記事で紹介した3件の実例が示すのは、AIが提示する「出典・URL・固有の数値」は、モデルの新旧を問わず構造的に信頼性が崩壊しているということです。権威URLを指定しても偽装されます。自サイトの内部リンクすら捏造されます。店舗情報の半分が作り話になっていることもあります。これは特殊な失敗例ではなく、誰にでも起こりうる構造的な現象です。
それでもAIを使う価値はあります。ただし使い方を間違えると、効率化どころか工数が増えます。ポイントは、リサーチと執筆を分離し、数字・URL・固有名詞を必ず人間がクリックして照合すること。この1点を守るだけで、AI活用の成否は大きく分かれます。
AIは魔法ではありません。地道な努力と、疑いながら使う冷静さが必要です。ただしその努力の先には、検証プロセスを組み込んだ上で2割の時短を実現するような、現実的な効率化が確かに存在します。ハルシネーションを前提に、AIを疑いながら使いこなす。これがライターとしてAIと付き合う正しい距離感だと、9年のフリーランス経験と2年のAI活用経験から私は考えています。
この記事のまとめ
ハルシネーション対策の本質は、AIを信頼することではなく、AIが信頼できない前提で運用する仕組みを組むことです。
- AIが提示する出典・URL・固有数値は、モデル新旧を問わず構造的に崩壊している
- リサーチと執筆の分離が最も効果的な防止策
- 「不明と答えさせる」「再点検させる」「検索AIで裏取り」の3プロンプトを組み合わせる
AIを活用した副業や効率化の全体像についてはAI副業とは?月千円が月10万円になった実体験と、稼げない人の共通点、生成AIの基礎から学び直したい方は生成AIの種類と個人での使い方|初心者が知るべき基礎・リスク・学び方、AIを活用したリサーチ手法の詳細は検索力の鍛え方|Webライター9年が伝える一次情報×AI検索のリサーチ術もあわせて参考にしてください。