情報があふれる時代なのに、「なかなか見つからない」「似た記事ばかりで結局わからない」と感じたことはありませんか?
検索に時間を溶かすのは、キーワードの選び方が悪いからではなく、問いそのものが曖昧なまま検索に入っているからです。
Webマーケター・Webライター歴9年の私は、2021年ごろからリサーチの仕方を一次情報ベースに切り替え、記事の信頼性で他のライターと差別化してきました。
2024年以降はNotebookLMとAI検索を組み合わせ、30分かかっていたリサーチを5分に短縮しています。
この記事では、検索力の基本から、プロのWebライターが実務で使う逆引きリサーチ術、AI検索時代のワークフロー、そして私自身が経験した失敗談まで一気に公開します。
読み終えたあとには、検索が単なる作業から、仕事を支える資産づくりに変わっているはずです。
この記事の結論
検索力とは、膨大な情報から必要なものを短時間で正確に見つけ出し、真偽を見極めて活用するスキルです。
- 検索精度は「キーワード力」より「検索意図の言語化」で決まる
- 信頼性で差別化するなら、一次情報の「ジャンル別使い分け」と「逆引きリサーチ」が効く
- AI検索は検索を置き換える道具ではなく、検索の前後を強化する道具

検索力とは?情報探索の本質と3つの構成要素
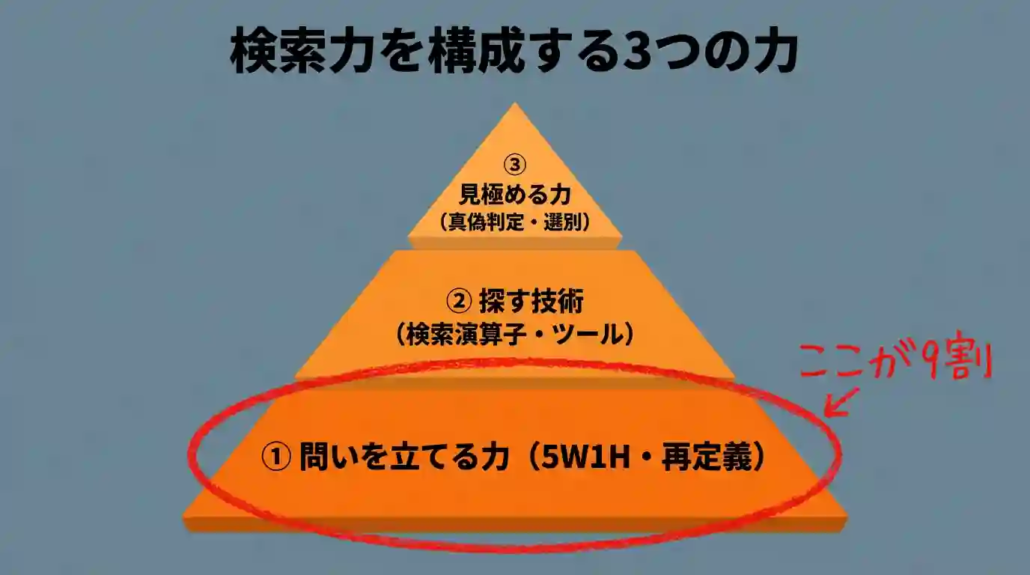
検索力とは、必要な情報を短時間で正確に見つけ、真偽を見極めて仕事に活かすスキルのことです。
キーワード入力の巧さではなく、問いの立て方・情報の選別・ファクトチェックという3つの力が束になって初めて機能します。
この章では、検索力の中身を分解し、なぜ多くの人が「うまく調べられない」と感じるのかを明らかにします。
検索力の1文定義と構成する3つの力
検索力は、以下の3つの力で成り立っています。
| 構成要素 | 意味 | 実務での現れ方 |
|---|---|---|
| 検索意図の言語化 | 自分が何を知りたいかを、検索エンジンが拾える言葉に翻訳する力 | 5W1Hで問いを具体化し、曖昧語を専門用語や言い換え語に置き換える |
| 情報選別 | 検索結果の中から信頼に足る情報だけを拾う力 | ドメイン(go.jp / ac.jp等)・発信者・更新日・根拠の有無で判断する |
| ファクトチェック | 拾った情報を一次ソースで裏取りする力 | 二次情報の出典を辿り、数値・年度・主体に矛盾がないかを確認する |
3つのうちどれか1つでも欠けると、検索結果は「それっぽい情報」で埋まってしまいます。そして、どれが弱いかは人によって違います。自分の弱点を把握することが、検索力を伸ばす最初の1歩です。
なぜ情報が見つからないのか──多くの人が陥る検索の罠
情報が見つからない原因のほとんどは、検索技術ではなく「理解したふりで止まっている」ことにあります。
私自身、Webライターを始めたばかりの頃は、まとめサイトの文章をそのまま信じて、記事の内容を表面的になぞっただけで「わかった」としていました。
検索が下手だったのではなく、深く理解しようとしていなかっただけです。
浅い理解のままでは、いい問いが立てられず、いいキーワードも浮かびません。
例えば「社内評価 落ちた 理由」という検索ワードには、「誰のことか」「どんな評価指標か」「どの時点のデータが必要か」が抜けています。
急いでいるときほどキーワードを何度も入れ替えたくなりますが、実は一度手を止めて、「自分は何を知りたかったのか」を言葉にし直すほうが早道です。
検索力がフリーランスの収入を左右する理由
検索力は、フリーランスにとって文章力や営業力よりも直接的に収入に効く武器です。
情報の信憑性で差別化できれば、記事の説得力が上がり、継続案件や単価アップにつながるからです。
Webライターやディレクターとしてフリーランスを続けてこられた理由を自分なりに振り返ると、一番大きかったのはこの検索力でした。
例えば「フリーランスでも社会保険に入れる可能性がある」という一次情報にたどり着くスキルは、同じ事実を美しい文章でまとめる力よりも、読者にとって価値があります。
そして今も、検索力は新しい仕事を探すとき、市場動向を把握するとき、業界の構造を読み解くときに効き続けています。フリーランスという働き方の全体像については、フリーランスとは?始め方・年収・職種をわかりやすく解説【完全ガイド】で詳しく触れています。Webライターに特化した実務の流れは、Webライターとは?もあわせて参考にしてください。
検索力を鍛える3ステップ思考法|探す前・探している間・見つけた後
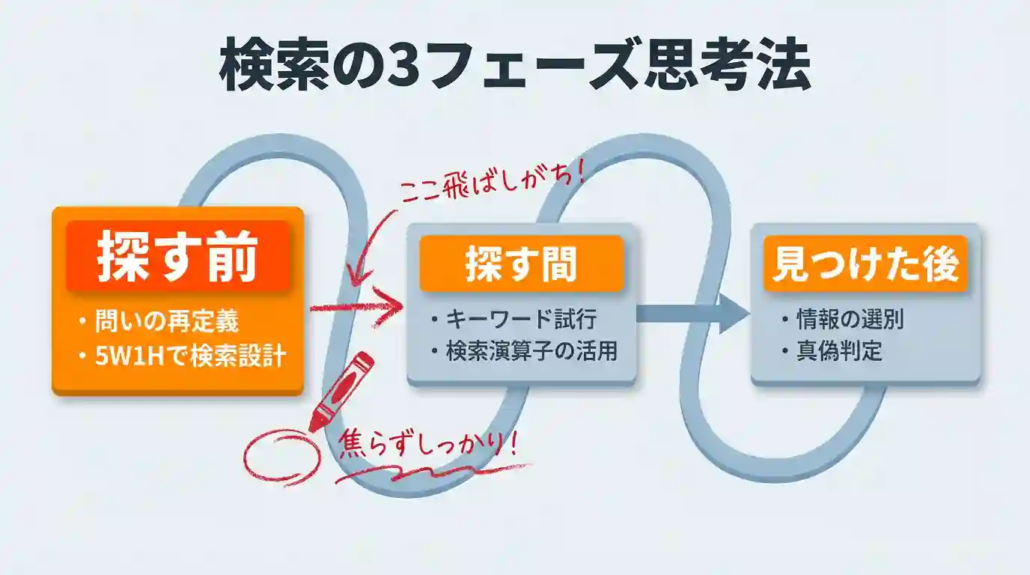
検索で時間を溶かす最大の原因は、キーワード選びではなく問いが曖昧なまま検索に入ることです。
検索は「探す前・探している間・見つけた後」の3段階に分けて思考するだけで、精度と速度が一気に変わります。
この章では、私が実務で使っている3ステップを具体例と一緒に紹介します。
ステップ1:探す前──問いの再定義と5W1Hによる検索準備
検索の精度は、検索ボックスに文字を打つ前に8割決まります。問いを具体化しないまま入力すると、検索結果は曖昧な情報で埋まるからです。
例えば「新卒 離職率 高い 業界」と打ちたくなったら、その前に次の問いを自分にぶつけてみてください。
- いつのデータが必要か(直近1年か、5年トレンドか)
- 離職率の定義は何か(入社3年以内か、1年以内か)
- 誰の数字が欲しいか(全体平均か、特定業界か)
- なぜその数字が必要か(記事の主張の根拠か、比較のためか)
この段階で使うのが5W1H(いつ・どこで・誰が・何を・なぜ・どのように)のフレームです。問いを言葉に置き換えることで、検索の軸が定まり、的外れな情報を最初から排除できます。5W1Hの具体的な使い方は、5W1Hとは?意味・使い方・順番・フレームワークとの違いまで徹底解説で詳しく解説しています。
ステップ2:探している間──キーワードの試行と検索演算子の活用
検索中の成果を左右するのは、最初の検索で満足せず、複数の表現を試す姿勢です。1発で当てにいくのではなく、ワードの入れ替え・具体化・抽象化を繰り返します。
私の場合、キーワードで結果が思うように出ないときは、次の順で動きます。
- 同じ意味の別の言葉に置き換える(例:「年収」→「所得」「給与」)
- 上位概念に抽象化する(例:「Webライター 単価」→「コンテンツ制作 単価相場」)
- 逆に下位概念で具体化する(例:「AI 導入」→「製造業 AI画像検査 導入事例」)
- それでも出ないときは、検索エンジン以外(AI検索・知恵袋・YouTube)に逃がす
この段階でもう1つ効くのが、検索演算子の活用です。演算子の詳細と具体例は、次の章の早見表で一気にまとめています。
ステップ3:見つけた後──結果の選別と情報源の真偽判定
検索結果の上位に出てきた記事を、そのまま信じてはいけません。上位表示は「多くの人に読まれている」ことを示すだけで、正確性を保証するものではないからです。
情報源の信頼性を判断するときに私が確認しているのは、次の4点です。
| チェック項目 | 見るべきポイント |
|---|---|
| ドメイン | go.jp(政府)/ac.jp(学術機関)/or.jp(非営利)は信頼度が高い |
| 発信者 | 執筆者名・肩書・所属が明記されているか |
| 更新日 | 何年何月の情報か、最新データとの差分があるか |
| 根拠 | 主観的な意見か、データ・出典が明示された記述か |
このチェックを習慣にするだけで、情報の質が一段上がります。検索はスタートラインであり、見つけた情報をどう読み解くかで成果物の質が決まります。見つけた情報をどう読み解いて顧客理解に変えるかは、顧客インサイトとは何か?定義・事例・見つけ方までわかる完全ガイドで詳しく触れています。
今日から使える検索テクニック|Google検索演算子7種と実務ヒント
検索演算子は単なる記号ではなく、情報の質そのものを変える道具です。同じキーワードでも、演算子を1つ加えるだけで、ノイズの少ない検索結果と信頼できる一次情報に一気に近づきます。この章では、私が実務で毎日のように使っている演算子7種と、サジェスト・専門検索エンジンの使い分けを紹介します。
Google検索で必ず使う検索演算子7種【早見表】
以下は、仕事のリサーチでそのまま使える検索演算子の一覧です。覚えるのは7個だけで十分で、組み合わせて使えば大抵のリサーチに対応できます。
| 演算子 | 機能 | 使用例 | 使いどころ |
|---|---|---|---|
| ” “ | 完全一致検索 | “AI導入事例” | 語順・表記そのままを含むページだけを抽出したいとき |
| – | 除外検索 | AI 導入 -製造業 | ノイズになる業界・キーワードをまとめて排除したいとき |
| site: | ドメイン指定 | 年収 site:go.jp | 官公庁・学術機関・特定メディアの情報だけを拾いたいとき |
| filetype: | ファイル形式指定 | 人事戦略 filetype:pdf | 企業IR資料・白書・研究論文などPDF資料を狙い撃ちしたいとき |
| * | ワイルドカード | “* の法則” | フレーズの一部が思い出せないとき、文脈で探したいとき |
| 期間指定 | 表示期間の絞り込み | 検索結果の「ツール」→「期間指定」で1年以内に設定 | 最新の統計・ニュース・トレンドだけを拾いたいとき |
| OR | 複数語の選択 | 副業 OR 兼業 確定申告 | 同じ意味の別の言葉を同時に拾いたいとき |
特にリサーチ業務で手放せないのは、ドメイン検索(site:)・PDF検索(filetype:)・期間指定の3つです。最新の公的データにたどり着くには、この3つの組み合わせが必要不可欠です。
サジェスト・画像・SNS検索の使いどころ
Google検索の演算子と並んで、検索の入り口を切り替える柔軟さも検索力の一部です。検索する場所を変えるだけで、今まで見えなかった情報が一気に見えることがあります。
- Googleサジェスト:入力途中に表示される関連語で、想定外の言い回しや視点に気づける
- 画像検索:言葉で表現しにくいもの・類似資料・UIやデザインの参考を探すときに有効
- X(旧Twitter)検索:リアルタイムの口コミ・現場の肌感・賛否両論の温度感を拾える
- YouTube検索:手順解説・実際の画面操作・初心者向けの概要把握に強い
- Yahoo!知恵袋:検索ボリュームがゼロに近い悩み言葉・浸透していない表現を拾える
私自身、「水あたり」のようにあまり浸透していない言葉でリサーチが詰まったときは、Google検索に固執せず、AI検索・知恵袋・YouTubeに逃がすことで30分〜1時間の迷走を避けています。
専門情報に強い検索エンジン・ツール
一般検索では見つけにくい専門情報には、分野別の検索エンジンを使い分けるのが最短ルートです。
| サービス | 得意分野 | 使いどころ |
|---|---|---|
| 国立国会図書館サーチ | 書籍・論文・公文書の横断検索 | 書籍や過去の公的資料を一気に探したいとき |
| J-STAGE | 日本の学協会発行の学術論文 | 国内研究の原論文を無料で読みたいとき |
| PubMed | 医療・ライフサイエンス系の英文論文 | 医療・健康・栄養の一次エビデンスを拾いたいとき |
| e-Stat(政府統計の総合窓口) | 日本の各省庁が公表する統計データ | 年次ベースの公的統計を原典で確認したいとき |
| J-Net21(中小企業基盤整備機構) | 中小企業・スタートアップ関連の一次情報 | 中小企業向けの支援制度や業界動向を調べたいとき |
業界特化型のプラットフォームを知っておくだけで、検索の打率と情報の信頼性が一段上がります。分野ごとに「まずここに当たる」というブックマークを持っておくと、リサーチの再現性も高まります。
プロのWebライターが実務で使うリサーチ術|信憑性で差別化する3つの手法
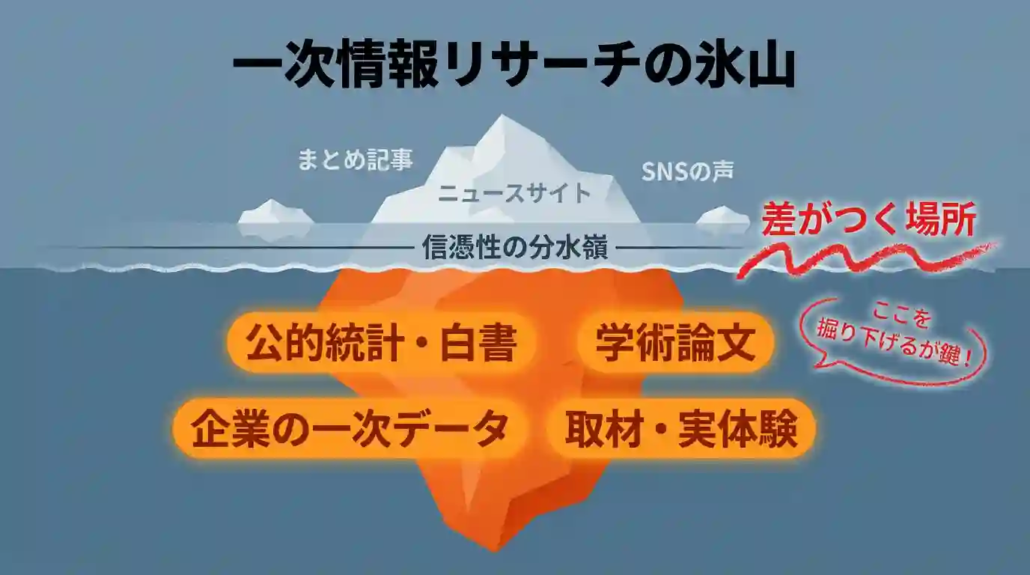
検索演算子の先にあるのが、信憑性を武器にするプロのリサーチです。
2021年ごろからSEOで情報の信頼性が段階的に重視されるようになり、一次情報を軸にした記事が継続案件として残るようになりました。
この章では、Webライター9年の実務から固まってきた3つのリサーチ術を紹介します。この領域は、Webライターとは?の業務実態とも深くつながっています。
一次情報の「ジャンル別使い分けマップ」
信頼できる一次情報を使うときの最大のコツは、ジャンルごとに「まずここに当たる」を決めておくことです。
検索で探すたびに迷っていたら時間がもったいないので、使い分けのマップを自分の中に持っておきます。
例えば「年収」を扱う記事の場合、私は次の優先順位で一次情報を使い分けています。
| 優先度 | 情報源 | 使いどころ |
|---|---|---|
| 1 | 国民生活基礎調査(厚労省) | 世帯・個人の所得分布のベース。実態に近い全体像を掴みたいとき |
| 2 | 民間給与実態統計調査(国税庁) | 零細企業を含む全体像が必要なとき。所得階級別の分布も取れる |
| 3 | 業界団体の独自調査 | 特定業界・職種の平均を取りたいとき |
| 参考 | 転職サイトの独自調査 | 上記で足りないとき、参考データとして補足する |
ここで気をつけたいのが、厚労省の「賃金構造基本統計調査」です。この調査は一部上場企業を中心とした事業所への調査のため、実態の平均より高めに出やすいという特徴があります。零細企業を含む一般的な年収を書きたい場合に使うと、読者が「自分の現実と違う」と感じる数字になってしまいます。同じ「年収の公的データ」でも、文脈に合わせた使い分けが必要です。
このジャンル別マップを持っておくと、リサーチの最初の5分で情報源の目星がつくようになり、案件全体の効率が大きく変わります。
金融・キャリア・医療・法律など、自分がよく扱うジャンルの「最初に当たる3つ」を決めておくだけでも、検索の再現性は段違いです。
上位競合の参照元を逆引きするリサーチ手法
信頼できる情報源の目星がつかないときに効くのが、上位競合サイトの参照元を逆引きする手法です。私はこの方法を2023年ごろから使うようになり、資料の目星がつかないテーマや、何十ページにもわたる膨大な資料を扱うテーマで特に重宝しています。
具体的な手順は以下の通りです。
- 検索上位の競合記事を5〜10本ざっと眺める
- そのなかで論理構成がロジカルで、根拠の出し方が丁寧な記事を2〜3本選ぶ
- 本文中の「〇〇によると」「△△調査では」といった出典箇所を拾う
- 記事末尾や文中リンクから、その資料のURLを実際に開く
- 資料の中身・年度・調査主体を確認し、それが自分の目的に合うベストな資料かを判定する
この手法のいいところは、自分では思いつかなかった統計源・白書・業界レポートに出会えることです。リサーチを続けていると、「このテーマを扱う人たちは、みんなこの資料を参照しているんだな」という地図ができてきます。情報源のレパートリー自体が広がるので、次回以降のリサーチがさらに速くなります。
ロジカルに書かれた競合記事は、いわば一次情報への「案内標識」です。直接Googleで当たるより、むしろ近道になる場面が多くあります。
公的データを「教科書的な文章」にしないための3つの工夫
一次情報を使うと信頼性は上がる反面、書き方を工夫しないと教科書的で固い文章になりがちです。読者が読みたくなる記事にするために、私は以下の3つを意識しています。
- 数字の後に、読者の生活スケールに落とし込む一文を添える(例:「年収400万円」→「月の手取りにすると約26万円で、家賃の上限目安は8万円前後」)
- データの弱点や前提を併記する(例:「ただしこの調査は一部上場企業の従業員が対象のため、実際の平均より高めに出る傾向があります」)
- 同じ資料の周辺ページにある補足情報を使い、異なる視点や自己批判を織り交ぜる
もちろん、メディアの方針として「数字を淡々と提示するスタイル」が求められる案件もあるので、この工夫はケースバイケースです。ただ、読者の想定イメージにぴったり合うように翻訳する姿勢を持っているかどうかで、同じ一次情報でも記事の厚みが変わってきます。
AI検索時代のリサーチワークフロー|Claude・Perplexity・NotebookLMの使い分け
AI検索は、従来のGoogle検索を置き換える道具ではなく、検索の前後を強化する道具です。
リサーチが速く正確になる一方で、AIに誤りがあっても気づきにくいというデメリットもあります。
この章では、Claude・Perplexity・NotebookLMをどう使い分け、どうファクトチェックしているかの実運用を公開します。生成AIの基礎を整理したい方は、生成AIの種類と個人での使い方|初心者が知るべき基礎・リスク・学び方もあわせて参考にしてください。
Claude と Perplexity の使い分け
私がAIリサーチに日常的に使っているのは、ClaudeとPerplexityの2つです。どちらもWeb検索対応なので事実参照ができますが、得意領域がはっきり違います。
| ツール | 得意領域 | 私の使いどころ |
|---|---|---|
| Perplexity | 浅く広い探索・ニュース調査・最新トピックの把握 | テーマの全体像を掴む最初のリサーチ/業界動向の概観をつかむ |
| Claude | 深掘り・ファクトチェック・文脈の整理 | 気になる論点の背景を掘る/数字や出典の裏取り/文章の構造化 |
役割分担のコツは、Perplexityで「問いの地図」を描いてから、Claudeで一点ずつ掘る流れを作ることです。いきなりClaudeに深掘りを頼むと、調べる範囲を絞りすぎて大事な周辺情報を取りこぼす場合があります。逆にPerplexityだけで完結させようとすると、情報が広く浅くなって根拠が弱くなります。両者を直列で使うと、どちらの弱点も補えます。
NotebookLMでリサーチ時間を30分→5分に短縮する運用
ページ数の多いPDF資料を扱うときに、NotebookLMは圧倒的に時短になります。
私は2024年ごろから使い始め、公的統計や業界資料のPDFを格納して、ページ数まで特定できる形で運用しています。
よく入れているのは次のような資料です。
- 厚労省の年収関連統計(毎年更新される長文PDF)
- 担当するクライアントの業界資料(白書・業界レポート・製品カタログ)
- 金融・キャリア・税務など、繰り返し参照するテーマの基礎資料
以前は、何十ページもあるPDFから該当データを探すのに30分前後かかっていました。
NotebookLMを使い始めてからは、同じ作業が5分前後で終わるようになりました。さらに、納品時に「何ページの何行目に掲載されている数字です」と出典を添えて提出できるようになり、クライアントからの信頼感も一段上がりました。
ページ数が多い資料ほど効果が大きいので、巨大なPDFを抱える案件ほど優位性が出ます。
継続案件のクライアントほど専門資料が厚くなりがちなので、NotebookLMとの相性は抜群です。
AIの回答を鵜呑みにしないファクトチェックの型
AIリサーチの最大の落とし穴は、誤りがあっても気づきにくいことです。
「ファクトチェックして」と指示するだけでは、AIは根拠ありげに間違った情報を提示してしまうので、以下のような運用をしています。
- 情報の信憑性をあらかじめランク付けするプロンプトを用意する(公的統計>業界団体>民間調査>一般記事、など)
- 「どの情報を、どの資料の、どの部分から取得したか」を明示的に回答させる
- 数字や年度については、公的な一次情報と必ず照らし合わせる
- AIが出した出典が実在するか、URLを直接開いて確認する
この運用に変えてから、AIのリサーチで起きがちな「それっぽい嘘」を大きく減らせました。
ポイントは、AIを「答えを出す人」ではなく「情報を整理して見せる人」として扱うことです。
最終判断は自分で下すという姿勢を崩さない限り、AIはリサーチの強力な味方になります。
見つけた情報を読み解く次のステップ
ここまでのリサーチで「信頼できる情報」を集められるようになります。ただし、情報は集めただけではまだ価値になりません。
顧客や読者にとっての意味を読み解いて初めて、記事やサービスのアウトプットに変わります。
見つけた情報をどう読み解いて、顧客の隠れたニーズ(インサイト)にまで昇華させるかは、顧客インサイトとは何か?定義・事例・見つけ方までわかる完全ガイドで詳しく解説しています。検索はスタートラインで、ゴールはその先にあります。
検索・リサーチでよくある失敗パターンと処方箋
検索力を最速で伸ばす近道は、他人の失敗談から学ぶことです。
成功事例は真似しづらいですが、失敗パターンは誰にでも同じ形で襲ってくるので、先に知っておくだけで回避できます。
この章では、私自身がやらかした3つの失敗と、それを二度と繰り返さないための処方箋を公開します。
失敗①:構成案時点は最新でも、納品時には古くなっていた
最新の公的データを使ったのに、納品時には最新ではなくなっていた失敗です。構成案を提出して、フィードバックをもらっているあいだにデータが更新され、納品する頃には1つ前の年度の情報になっていました。気づいたのはクライアントから指摘をもらった後です。
公的データは年度単位で更新されるため、構成案と納品のタイミングによっては、まさにその間に新しい数字が発表されているケースがあります。特に6月末・9月末・年度末の前後は、統計の更新が集中しやすい時期です。
この失敗以降、私は次のルールを運用しています。
- 公的情報や年度入りの情報を使った記事は、納品直前にもう一度最終チェックする
- 参照した資料のURLと年度をメモに残し、納品時に差分を機械的に確認する
- 更新頻度の高い統計は、記事テーマに関わらず「最新版の発表日」を把握しておく
シンプルですが、このチェックを挟むだけで同じ失敗は起きなくなりました。「リサーチの最終チェックは、書き終えたときではなく納品時」が、公的データを扱うときの鉄則です。
失敗②:キーワードが浮かばず30分〜1時間を溶かす
調べたいことは明確なのに、うまく引き出せるキーワードが浮かばないという失敗です。検索ボリュームがほぼゼロの言葉や、「水あたり」のようにあまり浸透していない表現を追いかけているときに起きやすく、気づけば30分〜1時間が消えています。
この状態に陥ったとき、私は次の順で手を動かします。
- 同じ意味の別の言葉に置き換える(言い換え)
- 上位概念に広げて抽象化する
- 逆に具体的な固有名詞や業界用語まで下ろして具体化する
- それでも出ないときは、Google検索以外の場所に逃がす(AI検索・Yahoo!知恵袋・YouTube・X)
特に効くのは、最後の「検索エンジン以外に逃がす」判断です。Googleで詰まるときは、その言葉がまだ検索データとして成熟していないサインなので、別のプラットフォームで同じ話題を探すと、かえって早く答えに出会えます。
検索が詰まったら時間をかけて粘るより、10分で切り替えるほうが効率的です。30分以上溶かしてから気づくより、最初から「10分ルール」で動くほうが、トータルの時間は短くなります。
失敗③:AIに気づけない誤りを紛れ込ませる
AIリサーチの怖さは、誤りがあってもそれっぽく書かれているため気づきにくいことです。特に「ファクトチェックして」とだけ指示して、AIが出した回答をそのまま使おうとすると、存在しない統計をでっち上げられたり、年度や調査主体をすり替えられたりします。
この失敗を繰り返さないために、私は次の習慣を徹底しています。
| チェック項目 | 具体的にどうするか |
|---|---|
| 数字の裏取り | AIが出した数字は、必ず公的な一次情報で照らし合わせる |
| 出典の実在確認 | AIが提示したURLを直接開き、本当にそのページが存在するか確認する |
| どこから取得したかの明示 | 「どの資料の、どの部分から取得したか」をAIに明確に回答させる |
| プロンプトのランク付け | 情報の信憑性を優先順位付けしたプロンプトを使う(公的>業界>民間>一般記事) |
AIリサーチは、使い方次第で武器にも事故の元にもなります。「AIに答えを出させる」のではなく、「AIに情報を整理させて、最終判断は自分がする」という姿勢を崩さない限り、強力な相棒になります。
検索結果を「資産化」する整理・再利用の習慣
検索は、1回ごとの使い捨て作業ではありません。記録と整理を挟むことで、同じテーマを調べ直す時間が減り、過去のリサーチがそのまま次の仕事の下地になります。この章では、私が日々のリサーチを資産に変えるために続けている最小限の運用を紹介します。
複数回使うデータはローカル保存とNotebookLM化
リサーチで一番コストがかかっているのは、同じ資料を何度も検索し直している時間です。特に繰り返し参照する公的データや業界資料は、最初から手元に置いてしまうほうが圧倒的に効率的です。
私の運用はシンプルです。
- 「知るぽると」や厚労省の年収関連資料のような、複数の案件で繰り返し使う資料はPDFでローカル保存しておく
- ページ数の多い資料はNotebookLMに格納して、ページ数まで特定できる状態にしておく
- 資料ごとに「どのテーマのとき使うか」を1行メモしておく
この3つを習慣にしておくだけで、新しい案件のリサーチ時間が目に見えて短くなります。最初に手間をかけておくほど、後のリサーチが軽くなる投資型の仕組みです。保存したPDFや記事を、目的に応じて呼び出せる状態にしておく整理術は、ブックマーク管理の決定版や仕事メモをなくさない方法も参考にしてください。
問いベースで情報を整理する発想
情報を整理するときは、「答え」ではなく「問い」を軸にすると、検索と思考が直結します。
例えば「◯◯業界の離職率はなぜ高いのか?」という問いをタイトルにして、そこに検索で集めた情報を紐づけていく形です。資料をジャンル分けして保存するより、「このページは、この問いに答えるために使う」という紐づけのほうが、あとで見返したときに使いやすくなります。
この発想を徹底すると、記事執筆の下準備そのものが情報整理になります。リサーチ→保存→執筆が分断された作業ではなく、1つの循環として回り始めます。Webクリップやノートアプリでこの仕組みを作る具体的な方法は、Webクリップ活用で情報収集・管理が爆速に!?で詳しく紹介しています。
よくある質問(FAQ)
検索力に関して、読者からよく寄せられる質問を7つ集めました。いずれも、私自身がリサーチ実務で直面してきた課題への回答です。自分の現在の検索パターンと照らし合わせながら読んでみてください。
検索力は誰でも鍛えられる?才能やセンスは必要?
検索力は、才能ではなく習慣で身につくスキルです。必要なのは、問いを具体化する姿勢と、情報源の信頼性を確認するクセの2つだけ。毎日の検索でこの2点を意識するだけで、3か月もあれば手応えが変わります。私自身、新人時代はまとめサイトを鵜呑みにしていた側でしたが、一次情報を辿る癖をつけた結果、リサーチ時間が半分になりました。
AI検索は従来のGoogle検索を置き換えるのか?
AI検索は、Google検索を置き換える道具ではなく、その前後を強化する道具です。浅く広い全体像の把握や、情報の整理には向いていますが、最新の一次情報や公的データの裏取りでは、今もGoogle検索と公式サイトへの直アクセスが最短ルートです。ClaudeとPerplexityを使い分けて「地図を描く→一次情報で確認」の流れを作ると、両者の強みを同時に取れます。
一番効果がある検索テクニックは何?
迷ったら、site:検索(ドメイン指定)から覚えてください。「キーワード site:go.jp」や「キーワード site:ac.jp」だけで、検索結果の信頼性が一気に変わります。演算子のなかでも、費用対効果が圧倒的に高いのがドメイン指定です。慣れてきたらfiletype:pdf・期間指定を足していくと、リサーチの精度がさらに上がります。
古いデータを最新だと誤認しないためのコツは?
公的データを使った記事は、納品直前にもう一度最終チェックするのが鉄則です。私自身、構成案時点では最新だったデータが、納品時には1つ前の年度になっていて、クライアントから指摘された経験があります。特に6月末・9月末・年度末の前後は公的統計の更新が集中しやすいので、この時期の案件ほど最終チェックが効きます。
信頼できる情報源をどう見分ければいい?
ドメイン・発信者・更新日・根拠の有無の4点で判断してください。go.jp(政府)・ac.jp(学術機関)・or.jp(非営利)は信頼度が高く、執筆者名と所属が明記されているかも重要な指標です。数字を扱う記事では、その数字が何年のどの調査から来ているのかまで遡り、同じ統計の最新版が出ていないかを確認する習慣をつけてください。
キーワードが浮かばないときはどうすればいい?
10分粘っても出ないキーワードは、検索エンジン以外に逃がしてください。私は「水あたり」のような浸透していない言葉で詰まったときに、AI検索・Yahoo!知恵袋・YouTubeで同じ話題を探すようにしています。Google検索で詰まるのは、その言葉がまだ検索データとして成熟していないサインなので、プラットフォームを変えるだけで答えに早く出会えます。
プロのリサーチと一般的な検索の違いは?
最大の違いは、ジャンル別の「まずここに当たる」情報源リストを持っているかどうかです。プロは毎回ゼロから検索するのではなく、自分が扱うテーマごとに信頼できる情報源を2〜3個持っていて、そこから当たります。年収ならまず国民生活基礎調査、というように。この「最初の一手」が固まっているかどうかで、リサーチの速度と品質が段違いになります。
まとめ|検索力は「複数回使えるデータベース」で加速する
検索力は、才能ではなく習慣で伸びるスキルです。この記事で紹介した手法のなかから、まずは1つだけ選んで、今日の仕事に組み込んでみてください。
9年のリサーチ経験を振り返って、当時の検索下手だった自分に1つだけアドバイスするなら、「複数回使うデータは、最初からデータベース化しておけ」と言いたいです。ローカル保存とNotebookLMを組み合わせるだけで、検索の効率は段違いに上がります。最初のひと手間で、その後の数年分のリサーチ時間を買い戻せる投資です。
文章力や営業力よりも、情報を正確に取りに行く力のほうが、実は継続案件を支えているというのが、フリーランスを9年続けてきた私の率直な実感です。情報に振り回されるのではなく、情報を自分の味方に変える第一歩として、この記事のテクニックを明日から使ってみてください。
検索力をさらに深めたい方には、フリーランスという働き方の全体像を整理したフリーランスとは?始め方・年収・職種をわかりやすく解説【完全ガイド】、集めた情報を顧客理解まで昇華させる顧客インサイトとは何か?定義・事例・見つけ方までわかる完全ガイド、AI活用の基礎を押さえる生成AIの種類と個人での使い方もあわせて参考にしてください。